

今回はスクレイピングの練習がてらZOZOTOWNのランキング商品のブランド名と商品名を引っこ抜いて表示させてみました。
目的のページはこちらhttp://zozo.jp/ranking/all-sales-men.html
ZOZOTOWNでスクレイピング
最終的な実行結果はこんな感じになりました。見づらさは気にしないでください。
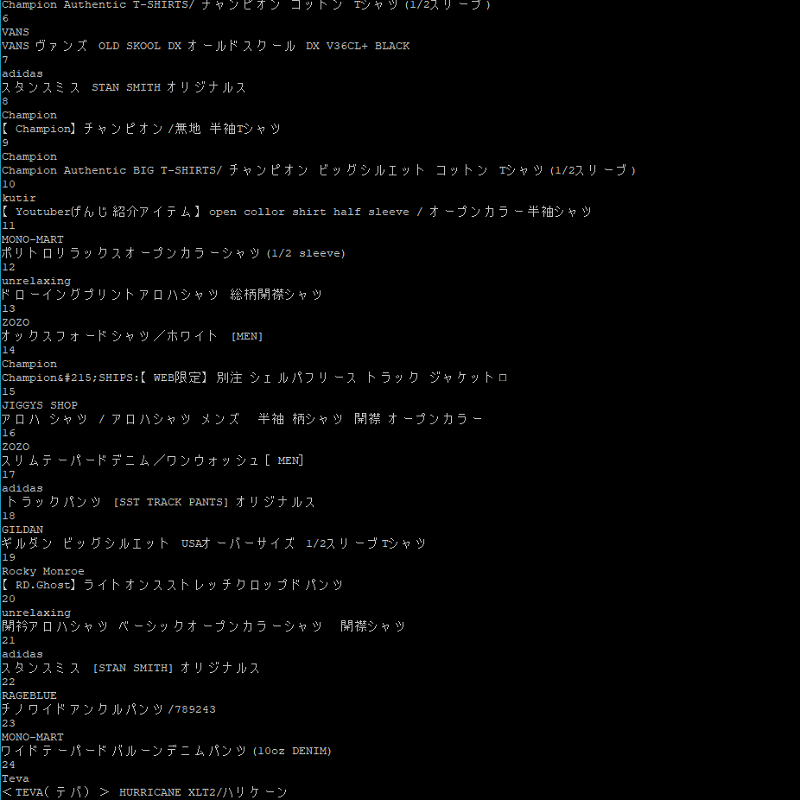
以前もスクレイピングをやったことがありましたが、今回は正規表現を使って抜き取ってみました。
rubyでスクレイピングと言えばnokogiriが良く使われているかと思います。私も初めて使ったときは軽くびっくりしました。
ですが、正規表現でも同じくらい楽にできました。というか正規表現を学んでからの方が文字の空白や改行の微調整といっためんどくさい作業も楽にできます。
今回私が一番苦戦したのは文字コードです。どうしても日本語で表示されず、x86のように16進数で表示されてかなり悩みました。
今回は文字コードとあとは正規表現を使ったスクレイピングについて少し書いてます。
文字コード
まず文字コードですが、私もよくわかっていません。
なんとなくなら理解したつもりでいます。
文字にはそれぞれ番号が割り振れています。例えば「あ」には8278のように。商品番号のようなものが文字にもあります。
これが何の役に立つかですが、
コンピュータが認識できるようになります。私たち人間は日本語を見て理解できますが機械は数字しか理解できません。「こんにちは」という文字をみても何と言っているのか理解はできません。なので、「こんにちは」という文字を数字で表して機械が読めるようにしてやろうというのが文字コードです。
文字コードが一つに統一されていたならばよかったですが、文字コードは一種類ではありません。複数あります。
なので文字コードによって数字の組み合わせがちがいます。そのため、プログラミングの際文字コードを変換する必要があります。
私は一般人なので詳しくは分かりません。Webで得た情報ですのであまり当てにしないでください。
ここからは実際のソースコードを見せて解説してきます。
ソースコード
[ruby]
require ‘nokogiri’
require ‘open-uri’
url = "http://zozo.jp/ranking/all-sales-men.html"
open(url,’r:SJIS’) do |request|
#puts request.charset #->iso-8859-1
doc = request.read.encode("UTF-8")
p doc.encoding #->#<Encoding:UTF-8>
ranking = doc.scan(/(.+?)<\/p>\s+<dl>\s+<dt>(.+?)<\/dt>/)
ranking.each_with_index do |item,i|
puts i+1
puts item[0]
puts item
end
end
[/ruby]
今回はopen-uriを使いました。
指定したuriにリクエストを送りレスポンスを受け取ることができます。
ZOZOTOWNはShift_JISという文字コードです。utf-8という文字コードが世界で広く使われています。ちょっと時代遅れを感じました。あとhttpsではなくhttpのも違和感がありました。
utf-8に変換させるためにopenの引数に’r:SJIS’と与えてやり、.encode(“UTF-8”)しutf-8文字コードに変換させました。
あとは特に変わったことはしていません。
なお標準添付ライブラリのKconvも使えました。Kconvとは返還前の文字コードを推測してくれ指定した文字コードに変換してくれます。
その時のコードはこちら
[ruby]</pre>
require ‘uri’
require ‘net/http’
require ‘open-uri’
require ‘kconv’
uri = URI.parse(‘http://zozo.jp/ranking/all-sales-men.html’)
Net::HTTP.version_1_2
Net::HTTP.start(uri.host,uri.port) do |http|
response = http.get(uri.request_uri)
doc = response.body
p doc.encoding
doc_utf8 = doc.toutf8
[/ruby]
後半部分は同じなので省略しました。
こっちはopenuriは使わずnet/httpを利用しました。やっていることは同じです。
nrt/httpはやれることが多いので色々な使い方がありますが今回はどっちでもいいですね。
次に正規表現についてですが、一から説明しようとなると大変なので私が勉強したページを紹介します。これを読めばきっと使えるようになります。その4まで読んでください。
初心者歓迎!手と目で覚える正規表現入門・その1「さまざまな形式の電話番号を検索しよう」
正規表現を使えば余分な空白や改行をきれいに整頓できるので使えるようになると非常に楽しいです。
という感じでZOZOTOWNのランキングをスクレイピングしてみました。
今回はブランド名と商品名だけでしたが、画像もできます。
今回集めたデータを今後どのように活用していくか色々考えていきたいですね。







